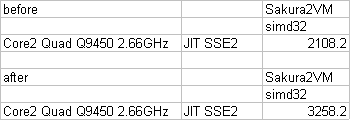
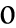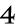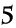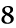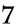前のSakura2VMのJITコンパイラの性能表のビフォア・アフターです。
と言ってもこれ、JITコンパイラ自体の性能向上って少ないんですよね………一応高速化はしたのですが。
それより、コード自体いじって、ループを少しアンロール(1ループで2頂点処理)したことが大きいです。まあ、とりあえず1.5倍ほど高速化しましたが、これ限定って感じで。(とりあえずC++のx86ネイティブより50%ほど高速に)
因みに、このパフォーマンスサンプルにはメモリの転送も含んでいます。結構メモリのネックも大きいので一応。
ただなんか、全般的に思ってたほど速くない、というか、まあ、十分に速いと言えば速いのですが、う〜〜〜ん。
JITコンパイルされたx86 SSE2のコードを見てもそんなに悪くないコードに見えるので………
Sakura2VM上で画像のソフトウェアレンダリングで、バイリニア補完の描画コードが、想定ほどのパフォーマンスが出てなくて………。でも、JITコンパイルされたSSE2のコード見てもそんなに悪くないように見えるんですよねぇ〜。
ただ、EntisGLS3のMMXの描画コードと速度を比較すると、数倍の差があると言う…。まあ、あのコードは異常にチューニングしたしなぁ…(普通に補完処理をMMXで書いた初期状態より2倍以上速くした記憶が…)
とりあえず、描画系はSakura2VMでのソフトウェア描画である必要は無いので(EntisGLS3の描画を呼び出すので)、将来の課題ですかねぇ…。
詞葉のインラインアセンブラでSakura2VMのSIMD命令を直書き限定ですが、C++のネイティブと同等かそれ以上の速度が出せる、ってことで…。後は、ARMのSIMD命令でどのくらい性能が出るか…。
|