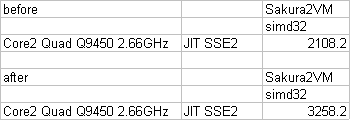
前のSakura2VMのJITコンパイラの性能表のビフォア・アフターです。
と言ってもこれ、JITコンパイラ自体の性能向上って少ないんですよね………一応高速化はしたのですが。
それより、コード自体いじって、ループを少しアンロール(1ループで2頂点処理)したことが大きいです。まあ、とりあえず1.5倍ほど高速化しましたが、これ限定って感じで。(とりあえずC++のx86ネイティブより50%ほど高速に)
因みに、このパフォーマンスサンプルにはメモリの転送も含んでいます。結構メモリのネックも大きいので一応。
ただなんか、全般的に思ってたほど速くない、というか、まあ、十分に速いと言えば速いのですが、う〜〜〜ん。
JITコンパイルされたx86 SSE2のコードを見てもそんなに悪くないコードに見えるので………
Sakura2VM上で画像のソフトウェアレンダリングで、バイリニア補完の描画コードが、想定ほどのパフォーマンスが出てなくて………。でも、JITコンパイルされたSSE2のコード見てもそんなに悪くないように見えるんですよねぇ〜。
ただ、EntisGLS3のMMXの描画コードと速度を比較すると、数倍の差があると言う…。まあ、あのコードは異常にチューニングしたしなぁ…(普通に補完処理をMMXで書いた初期状態より2倍以上速くした記憶が…)
とりあえず、描画系はSakura2VMでのソフトウェア描画である必要は無いので(EntisGLS3の描画を呼び出すので)、将来の課題ですかねぇ…。
詞葉のインラインアセンブラでSakura2VMのSIMD命令を直書き限定ですが、C++のネイティブと同等かそれ以上の速度が出せる、ってことで…。後は、ARMのSIMD命令でどのくらい性能が出るか…。
次回作、と言うか、次回作の前に出す予定のタイトルです。
F-ZERO に STG 要素を少しだけ追加したようなゲームにする予定です。
EntisGLS4s のサンプルとして作るゲームなので、ソースコードは全部付ける予定です。
冬コミを目指しますが、なんやかんやで来年になりそうな気も…
因みに、EntisGLS4s は動作チェックを兼ねたサンプルコードを書きつつと言う感じですが、現状、サンプルが9つですね。あと数個は予定しています。ライブラリの主要どころをざっくり網羅できるようにするつもりなので。
あと、ARM用のJITコンパイラも…。時間があればすぐにでもという感じですが、後回しかなぁ。
ARM用JITコンパイラは基本的にARMv6以降のみにしようかと思っています。(thumbモードの)ARMv5とARMv6、更にはVFPや
NEONを使う場合には、ARMv6以降では結構共通化できると思うのですが、ARMv5は別物になりそうな気がするので、そこまでARMv5にコストは
掛けられないかなと。(一方で、486用JITとSSE2用JITは共通部分が多くて、汎用JITコンパイラクラスから派生した486用JITクラスを派
生してSSE2用のJITクラスを実装しています)
別にJITコンパイラがないと動作しないわけじゃないですし、実行速度がちょっと遅いだけで。
まだ、同人ゲームの本格的な製作に入れていないと言う発表みたいなものですがw
EntisGLS4s の実行プラットフォームである
Sakura2VM(仮想マシン)の性能(の一面)を見てみるサンプルコードを書いたのでちょっと手持ちの環境で色々実行してみました。(サンプルコード
はEntisGLS4sに同梱するために作っているもので、リリースの段階での性能は異なっている可能性があります)
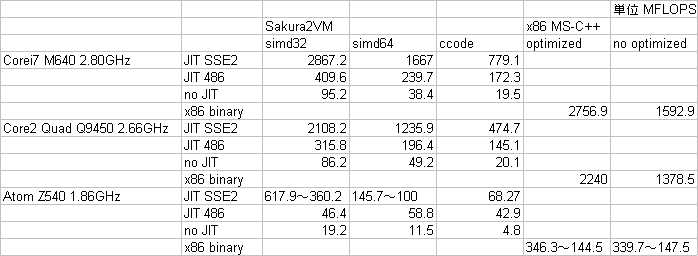
まず、表中の数字ですが単位はMFLOPSで、4x4の行列に4次元ベクトルを掛けて4次元ベクトルを得る演算を連続的に行って(シングルスレッド)、掛かった時間から実効的な処理能力を求めています。
各行は実行したCPUとバイナリを表していて、「JIT
SSE2」はSakura2仮想マシンのコードをSSE2コードに変換して実行した場合、同様に「JIT 486」は486互換コード、「no
JIT」は逐次実行した場合、「x86 binary」はC++でそのままコンパイルしたネイティブコードです。
各列はソースコードとコンパイルの違いを表していて、ccodeはC++のソースを詞葉コンパイラでコンパイルしたSakura2仮想マシンコード、
「x86 MS-C++」の「optimized」「no
optimized」は同じソースをMS-C++でコンパイルしたバイナリです。「simd32」と「simd64」はSakura2仮想マシン用に詞葉
インラインアセンブラでで記述したコードで、simd32はSakura2仮想マシンの128ビットSIMD命令を利用します。simd64はインライン
アセンブラを使用しますが、通常の64ビット浮動小数点命令を使用しています。但し、JITコンパイルする際にペアリングされ、SSE2ではmulpd、
addpd命令で実行されます。
色々違うCPUで実行するとCPUの傾向が違っていて面白いです。
まあ、それ以前に大量の頂点処理やピクセル処理をする場合には、JIT SSE2 じゃないと速度的に色々ヤバイなって感じはしますが。(初めからそのつもりで作ってはいるのですがw)
あと、SSE2でのsimd32は、この倍位の数値が出る予定だったのですが、こんなもんなのでしょうか?
x86 binary の方は x87 FPU コードなのですが、私の経験則としてこのような行列演算ではSSEでもFPUでも速度が違わないということがあったので、きっとこんなものなのでしょう。
一方で、ピクセルなどの飽和を伴うような整数演算ではかなり差が出ると思います。(Sakura2のインラインアセンブラで記述した方が速くなると思います、多分)
それにしても、Atom Z540 は一体何なのでしょうw
こんなに浮動小数点演算に癖のあるCPUだとは思っていませんでした。
特に、x86 binary
の最適化有り無しで速度が変わらないのが笑えます。もちろんその理由は簡単に推測出来るのですが…。つまり、Atomは古典的(486やP5アーキテク
チャ)な実行のされ方をするので、FPU命令は同時に複数実行されることがまずない。一方で、浮動小数点演算が終わるまでの間、その次にある整数命令はど
んどん実行できる。結果、最適化しなくてもFPU命令の間にある整数命令などが隠れて見えなくなるということでしょう。
あと、SSE2での倍精度浮動小数点演算の遅さは………Atomはやる気が無いのでしょうか?w
|